第五章 面向对象编程

正如我们将看到的,一个好的架构的基础是对面向对象设计(OO)原理的理解和应用。那面向对象是什么?
对这个问题的一个答案是“数据和函数的结合”。虽然经常被引用,但这是一个非常令人不满意的答案,因为它意味着o.f()与f(o)有某种不同。这是荒谬的。在1966年,当时Dahl和Nygaard把函数调用栈帧移动到了堆中,并发明了面向对象,在这之前,程序员就有把数据结构传递给了函数行为。
对这个问题的另一个常见的答案是“模拟现实世界的一种方式”。这是一个回避的答案。 “模拟现实世界”究竟是什么意思,为什么这我们想要做的事呢?也许这个表述意在暗示面向对象使得软件更容易理解,因为它与现实世界有着更密切的关系-但是即使这个说法是回避的,也是过于宽泛的定义。它没有告诉我们什么是面向对象。
有些人回溯到三个神奇的词语来解释面向对象的本质:封装,继承和多态。其含义是面向对象是这三件事的恰当混合,或者至少面向对象语言必须支持这三件事。
我们依次看看这些概念。
封装
引用封装作为面向对象定义的一部分的原因是面向对象语言提供简单而有效的数据和函数封装。 因此,一行代码可以牵动一组密切关联的数据和函数。 除此之外,数据是隐藏的,只有一些函数才知道这些数据。 我们将这个概念看作是一个类的私有数据成员和公共成员函数。
这个想法当然不是面向对象所特有的。 的确,我们在C中有完美的封装。考虑这个简单的C程序:
point.h
-------------------------------
struct Point;
struct Point* makePoint(double x, double y);
double distance (struct Point *p1, struct Point *p2);
point.c
-------------------------------
#include "point.h"
#include <stdlib.h>
#include <math.h>
struct Point {
double x,y;
};
struct Point* makepoint(double x, double y) {
struct Point* p = malloc(sizeof(struct Point));
p->x = x;
p->y = y;
return p;
}
double distance(struct Point* p1, struct Point* p2) {
double dx = p1->x - p2->x;
double dy = p1->y - p2->y;
return sqrt(dx*dx+dy*dy);
}
使用point.h的用户不能访问struct Point的成员。虽然可以调用makePoint()和distance()函数,但是绝对对Point中数据结构和函数的实现一无所知。
这是完美的封装,但并非面向对象语言。C语言程序员总是这样做这件事,我们预先在头文件里声明数据结构和函数,然后在实现的文件里写实现。我们代码的使用者不会访问实现文件里的元素。
但是C++语言的面向对象到来了,它突破了C语言的完美封装。
point.h
-------------------------------
class Point {
public:
Point(double x, double y);
double distance(const Point& p) const;
private:
double x;
double y;
};
point.cc
-------------------------------
#include "point.h"
#include <math.h>
Point::Point(double x, double y)
: x(x), y(y)
{}
double Point::distance(const Point& p) const {
double dx = x-p.x;
double dy = y-p.y;
return sqrt(dx*dx + dy*dy);
}
头文件point.h的客户端知道成员变量x和y,编译器虽然保护他们避免被访问到,但是客户端还是知道他们存在的,比如,如果成员的名字改变了,point.cc文件得重新编译了,封装就被打破了。
事实上,部分修复封装的方式是将public,private和protected的关键字引入到语言中。 然而,这是编译器可以在头文件中查看到这些变量的技术需要所必需的。 Java和C#只是简单地废除了头和实现的拆分,从而更加弱化了封装。 在这些语言中,不可能把一个类的声明和定义分开。 由于这些原因,很难接受面向对象依赖于强封装。 事实上,许多面向对象语言几乎没有或者根本没有强制封装。
面向对象当然依赖于程序员的良好行为,而不是绕过封装的数据。即便如此,声称提供面向对象的语言也只是削弱了我们曾经用C语言时的完美的封装。
继承
如果面向对象语言没有给我们更好的封装,那么他们肯定会给我们继承特性。
可能吧,继承就是在一个封闭范围内重新声明一组变量和函数。 这是C程序员在有面向对象语言之前就能手动做的事情。
考虑以下这个程序和原来的point.h C程序:
namedPoint.h
----------------------------
struct NamedPoint;
struct NamedPoint* makeNamedPoint(double x, double y, char* name);
void setName(struct NamedPoint* np, char* name);
char* getName(struct NamedPoint* np);
namedPoint.c
----------------------------
#include "namedPoint.h"
#include <stdlib.h>
struct NamedPoint {
double x,y;
char* name;
};
struct NamedPoint* makeNamedPoint(double x, double y, char* name) {
struct NamedPoint* p = malloc(sizeof(struct NamedPoint));
p->x = x;
p->y = y;
p->name = name;
return p;
}
void setName(struct NamedPoint* np, char* name) {
np->name = name;
}
char* getName(struct NamedPoint* np) {
return np->name;
main.c
----------------------------
#include "point.h"
#include "namedPoint.h"
#include <stdio.h>
int main(int ac, char** av) {
struct NamedPoint* origin = makeNamedPoint(0.0, 0.0, "origin");
struct NamedPoint* upperRight = makeNamedPoint (1.0, 1.0, "upperRight");
printf("distance=%f\n",
distance(
(struct Point*) origin,
(struct Point*) upperRight));
}
如果你仔细看main程序,你会发现NamedPoint数据结构是Point数据结构的派生,这是因为NamedPoint声明的前两个成员和Point中是一样的。简言之,NamedPoint可以伪装成Point来用,因为NamePoint是Point的超集,包含了和Point中相同的且顺序一致的成员。
这种伪装是程序员在面向对象出现之前的常见做法。事实上,这样的技巧是C++如何实现单一的继承的方法。
因此,我们可以说在面向对象语言发明之前就已经有了一种继承。 但是,这个陈述不是真的。虽然我们有这个技巧,但它不如真正的继承方便。 而且,通过这种技巧来实现多重继承是相当困难的。
还要注意,在main.c中,我得将NamedPoint参数转换为Point。在一个真正的面向对象的语言中,这种向上转型是隐含的。
可以这么说,虽然面向对象语言并没有给我们带来全新的东西,但它确实使数据结构的伪装变得更为方便。
回顾一下:我们对面向对象的封装一分都不给,也许可以给继承半分。到目前为止,这不是一个很好的分数。
但还有一个特性需要考虑。
多态
在面向对象语言之前我们用过多态特性吗?当然有,考虑简单地C的copy程序。
#include <stdio.h>
void copy() {
int c;
while ((c=getchar()) != EOF)
putchar(c);
}
getchar()函数从STDIN中读取,STDIN是哪种设备?putchar()函数写入STDOUT里,这又是哪种设备?这些函数是多态的,他们的行为依赖于STDIN和STDOUT的类型。
就像STDIN和STDOUT是Java风格的接口一样,每个设备都有各自的实现。当然,在C程序的示例中没有接口,那么调用getchar()如何实际地得到字符读取的设备驱动的交付呢?
这个问题的答案非常简单。UNIX操作系统要求每个IO设备驱动程序提供五个标准函数:open, close, read, write和seek。这些函数的签名对于每个IO驱动程序都必须相同。
FILE数据结构包含五个函数指针。在我们的例子中,它可能看起来像这样:
struct FILE {
void (*open)(char* name, int mode);
void (*close)();
int (*read)();
void (*write)(char);
void (*seek)(long index, int mode);
};
控制台的IO驱动程序将定义这些函数,上传FILE的数据结构的地址,类似:
#include "file.h"
void open(char* name, int mode) {/*...*/}
void close() {/*...*/};
int read() {int c;/*...*/ return c;}
void write(char c) {/*...*/}
void seek(long index, int mode) {/*...*/}
struct FILE console = {open, close, read, write, seek};
现在如果STDIN被定义成FILE*,如果它指向控制台的数据结构,那么getchar()的实现也许是这样的:
extern struct FILE* STDIN;
int getchar() {
return STDIN->read();
}
换句话说,getchar()只是调用由STDIN指向的FILE数据结构的read指针指向的函数。
这个简单的技巧是面向对象所有多态的基础。例如,在C++中,类中的每个虚函数在一个名为vtable的表中都有一个指针,所有对虚函数的调用都通过该表。派生类的构造函数只是将这些函数的版本加载到正在创建的对象的vtable中。
多态说到底是指向函数的指针的应用。自从20世纪40年代后期冯诺依曼架构首次实现以来,程序员一直在使用函数指针来实现多态行为。换句话说,面向对象没有提供任何新东西。
啊,但这不太对。面向对象语言可能没有给我们带来多态性,但是它使得它更安全和更方便。
显式使用函数指针来创建多态行为的问题是:指向函数的指针是危险的。这种使用是由一系列手动约定所驱动的。你必须记得遵循约定来初始化这些指针。你必须记住按照约定通过这些指针调用你的所有函数。如果任何程序员没有记住这些约定,那么由此产生的bug可能会很难追查和消除。
面向对象语言消除了这些惯例,从而消除了这些危险。使用面向对象语言使得多态性变得微不足道。这些都是一个老C程序员只能梦想的巨大的力量。在此基础上,我们可以得出结论,面向对象描述控制间接转移的规则。
多态的力量
多态性有什么好处?为了更好地欣赏它的魅力,让我们重新考虑示例copy程序。如果创建一个新的IO设备,该程序会发生什么?假设我们要使用copy程序将数据从手写识别设备复制到语音合成器设备:我们如何才能更改copy程序以使其与这些新设备一起工作?
我们根本不需要任何改变!事实上,我们甚至不需要重新编译copy程序。为什么?因为copy程序的源代码不依赖于IO驱动程序的源代码。只要这些IO驱动程序实现FILE定义的五个标准函数,copy程序将乐于使用它们。
简而言之,IO设备已经成为copy程序的插件。
为什么UNIX操作系统要做IO设备插件?因为我们在20世纪50年代后期才了解到,我们的程序应该是独立于设备的。为什么?因为我们写了许多依赖于设备的程序,只是发现我们希望使用不同的设备,但程序还是做同样的工作。
例如,我们经常编写从卡片组读取输入数据的程序,然后打出新的卡片组作为输出。后来,我们的客户停止给我们一副牌,开始给我们卷轴磁带。这非常不方便,因为这意味着重写原始程序的大部分。如果同一个程序与卡片或磁带互换,这将是非常方便的。
为了支持这种IO设备独立性,插件架构被发明出来,并且自推出以来几乎已经在各种操作系统中实现了。即便如此,大多数程序员并没有将自己的想法扩展到自己的程序中,因为使用函数指针是危险的。
面向对象允许插件架构在任何地方用于任何事情。
依赖倒置
想象一下,在安全和方便的多态性机制可用之前,软件是什么样的。在典型的调用树中,main函数调用高层函数,高层函数调用中级函数,中层函数调用低层函数。然而,在那个调用树中,源代码的依赖关系客观地跟随着控制流程(图5.1)。
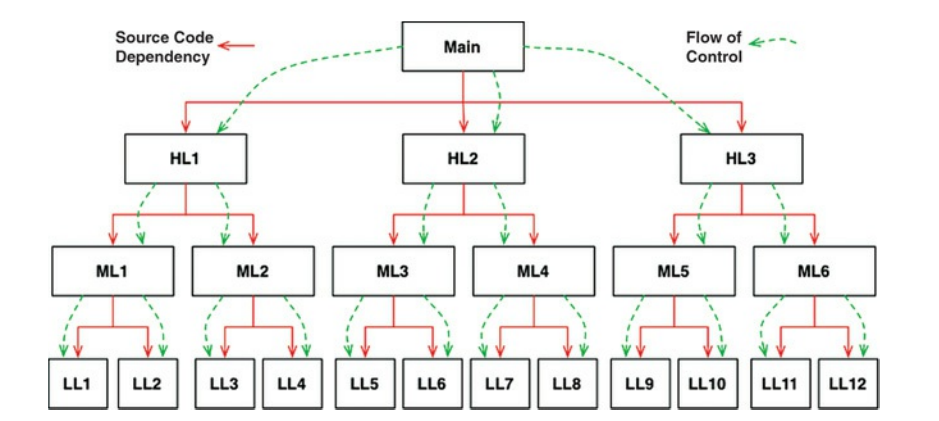
图5.1 源代码依赖性与控制流
对于main函数调用其中一个高层函数,它不得不将包含该函数的模块的名称包含在代码中,在C中,这是一个#include语句。在Java中,这是一个import语句。在C#中,它是一个using语句。事实上,每个调用者都被迫提到包含被调用者的模块的名称。
这个要求让软件架构师别无选择。控制流由系统的行为决定,而源代码依赖性则由控制流程决定。然而,当多态性发挥作用时,可能会发生非常不同的事情(图5.2)。
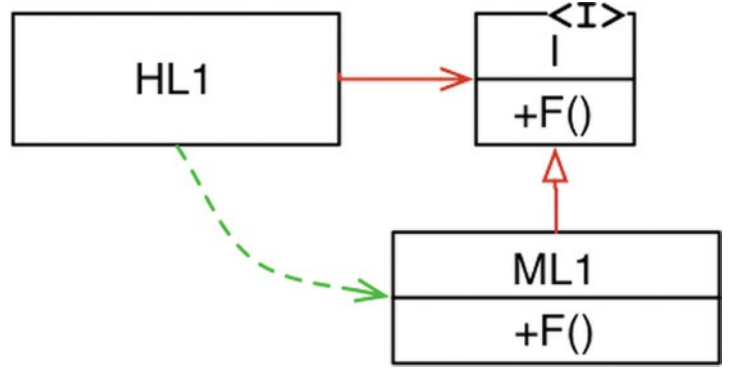
图5.2 依赖倒置
在图5.2中,模块HL1调用模块ML1中的F()函数。它通过接口调用这个函数是一个源代码的设计。在运行时,该接口不存在。HL1只是在ML1内调用F()。
但是请注意,与控制流相比,ML1和接口I之间的源代码依赖关系(继承关系)指向相反的方向。这就是所谓的依赖倒置,它对软件架构师的影响是深刻的。
面向对象语言提供安全和方便的多态性的事实意味着任何源代码依赖性,无论它在哪里,都可以被颠倒。
现在回头看看图5.1中的调用树,以及它的许多源代码依赖关系。任何这些源代码的依赖关系都可以通过在它们之间插入接口来解决。
通过这种方法,使用面向对象语言编写的系统中的软件架构师可以绝对控制系统中所有源代码依赖的方向。他们没有限制把这些依赖关系与控制流程联系起来。无论调用哪个模块以及调用哪个模块,软件架构师都可以在任一方向指定源代码依赖性。
这就是力量!这是面向对象提供的力量。这就是面向对象的真正意义-至少从架构师的角度来看是这样。
你可以用这个力量做什么?例如,您可以重新排列系统的源代码依赖关系,以便database(数据库)和UI(用户界面)依赖business rules(业务规则)(图5.3),而不是相反。
 图5.3 数据库和UI依赖于业务规则
图5.3 数据库和UI依赖于业务规则
这意味着UI和数据库可以是业务规则的插件。这意味着业务规则的源代码永远不会提到UI或数据库。
因此,业务规则,UI和数据库可以被编译成与源代码具有相同依赖性的三个单独的组件或部署单元(例如,jar文件,DLL或Gem文件)。包含业务规则的组件将不依赖于包含UI和数据库的组件。
反过来,业务规则可以独立于UI和数据库进行部署。UI或数据库的更改不需要对业务规则有任何影响。这些组件可以单独和独立部署。
简而言之,当组件中的源代码发生变化时,只有该组件需要重新部署。这是独立的可部署性。
如果系统中的模块可以独立部署,则可以由不同的团队独立开发。这是独立的可开发性。
小结
什么是面向对象?这个问题有很多意见和很多答案。但是,对于软件架构师来说,答案很明显:面向对象是通过使用多态性来获得对系统中每个源代码依赖的绝对控制的能力。它允许架构师创建一个插件架构,其中包含高层策略的模块独立于包含低层细节的模块。底层的细节被放到插件模块中,这些插件模块可以独立于包含高层策略的模块进行部署和开发。