第十七章 边界:画线

软件架构是绘制线的艺术,这些线我称为边界。这些边界将软件元素彼此分开,并限制一方对其他方面的了解。其中一些线条在整个项目中很早就被提取出来了——甚至在没有写代码之前。其他的线很晚才画出。那些初期就画出的线是为了尽可能长时间地推迟决定,并且使这些决定不会污染核心业务逻辑。
回想一下,架构师的目标是最大限度地减少构建和维护所需系统所需的人力资源。这是什么样的人力(people-power)呢?耦合——特别是耦合到过早的决定。
哪种决策是不成熟的?与系统的业务需求(用例)无关的决策。这些包括关于框架,数据库,Web服务器,实用程序库,依赖注入等的决定。一个好的系统架构就是像这样的决策是辅助的和可延迟的。一个好的系统架构不依赖于这些决定。一个好的系统架构允许在最后可能的时刻做出这些决定,而不会产生很大影响。
悲伤故事二则
这是关于P公司悲惨的故事,这是一个过早做出决定的警示。在20世纪80年代,P公司的创始人写了一个简单的单片桌面应用程序。他们获得了巨大的成功,并在20世纪90年代将产品发展成为流行和成功的桌面GUI应用程序。
但是,在20世纪90年代后期,网络成了一股力量。突然之间,每个人都必须有一个网络解决方案,P公司也不例外。P的客户在网上大肆宣传该产品的一个版本。为了满足这个需求,公司聘请了二十几位Java程序员,并着手开展一个项目,使他们的产品网络化。
Java程序员在他们头脑中已经想好了服务器群1,所以他们采用了一个丰富的三层“架构”,他们可以这样分配服务器群。将有用于GUI的服务器,用于中间件的服务器以及用于数据库的服务器。
程序员很早就决定所有域对象都有三个实例:一个在GUI层,一个在中间件层,一个在数据库层。由于这些实例存在于不同的机器上,因此建立了一个丰富的处理器间和层间通信系统。层之间的方法调用被转换为对象,序列化,并通过线路编组。
现在想象一下,如何实现一个简单的功能,如添加一个新的字段到现有的记录。这个字段必须被添加到所有三层的类中,以及几个层间的信息中。由于数据传送是双向的,需要设计四个消息协议。2每个协议都有一个发送和接收端,所以需要八个协议处理程序。必须构建三个可执行文件,每个包含三个更新的业务对象,四个新消息和八个新的处理程序。
考虑那些可执行文件为了实现最简单的功能而必须做的事情。想想所有的对象实例化,所有的序列化,所有的编组和解封装,所有的消息构建和解析,所有的套接字通信,超时管理器,重试场景以及所有其他你必须做的事情,最后完成一件简单的事情。
当然,在开发过程中,程序员没有服务器群。事实上,他们只是在一台机器上运行三个不同进程的全部三个可执行文件。他们这样开发了好几年。但他们确信他们的架构是正确的。所以即使它们在一台机器上执行,它们仍然继续所有的对象实例化,所有的序列化,所有的编组和解组,所有的消息构建和解析,所有的套接字通信,以及所有额外的东西在一台机器。
讽刺的是,P公司从来没有出售过需要服务器群的系统。他们曾经部署的每个系统都是一台服务器。在这个单一的服务器中,所有三个可执行文件都继续了所有的对象实例化,所有的序列化,所有的编组和解组,所有的消息构建和解析,所有的套接字通信以及所有额外的东西,从来不存在的服务器群,永远不会。
悲剧在于,架构师通过提前做出决定,大大增加了开发的付出。
P公司的故事不是个例。我在很多地方见过很多次。事实上,P公司这是这些地方的缩影。
但是还有比P公司更糟的。
考虑一下公司车辆管理的当地企业W公司。他们最近聘请了一名“架构师”来控制(control)他们的抹布标签软件。而且,让我告诉你,control是这个人的中间名。他很快意识到,这个小小的操作所需要的是一个全面的,企业规模的(enterprise-scale),面向服务的“架构”(service-oriented “ARCHITECTURE”)。他创建了一个业务中所有不同“对象”的巨大领域模型,设计了一套服务来管理这些领域的对象,并把所有的开发人员送去”地狱“的路上。举一个简单的例子,假设你想把联系人的姓名,地址和电话号码添加到销售记录中。你必须访问ServiceRegistry请求ContactService的服务ID。然后你必须发送一个CreateContact消息到ContactService。当然,这个消息有几十个字段,都必须有有效的数据——程序员无法访问的数据,因为程序员都是名字,地址和电话号码。3伪造数据后,程序员必须将新创建的联系人的ID卡入销售记录,并将UpdateContact消息发送给SaleRecordService。
当然,无论测试任何东西你都必须逐一启动所有必要的服务,启动消息总线和BPel服务器等等,然后,随着这些消息从服务到服务间的传输,出现了传输延迟,并在一个又一个队列中等待。
然后,如果你想添加一个新功能,那么,你可以想像,所有组件的耦合,庞大的WSDL数量都需要改变,还得重新部署......
通过比较,地狱变得似乎是一个不错的地方。
围绕服务构建的软件系统没有任何内在的错误。W公司的错误是过早地采用和执行了一套承诺SoA的工具——也就是说,过早地采用了大量的领域对象服务。这些错误的代价是纯粹的个人时间,人们成群结队地冲进SoA漩涡。
我可以继续描述一个又一个的架构失败的例子。但是让我们来讨论一下架构成功的例子。
FitNesse项目
我的儿子Micah和我在2001年开始了FitNesse的工作。这个想法是创建一个简单的wiki来包装Ward Cunningham的FIT工具来编写验收测试。
这是在Maven“解决”jar文件问题之前的时候。我坚持认为,我们所做的任何事情都不应该要求人们下载多个jar文件。我把这个规则称为“下载即用”。这个规则推动了我们的许多决定。
第一个决定之一是编写我们自己的Web服务器,专门针对FitNesse的需求。这听起来很荒谬。即使在2001年,也有很多我们可以使用的开源Web服务器。然而,编写我们自己的服务器是一个非常好的决定,因为一个简单的web服务器是一个非常简单的软件,它可以让我们推迟任何web框架的决定,直到很久以后。
另一个早期的决定是避免考虑数据库。我们总惦记着MySQL,但我们故意拖延了这个决定,采用了一个使决策无关的设计。这种设计只是简单地在所有数据访问和数据存储库本身之间建立一个接口。
我们把数据访问方法放到一个名为WikiPage的接口中。这些方法提供了我们需要的查找,获取和保存页面的所有功能。当然,我们一开始并没有实现这些方法;当我们的功能不涉及获取和保存数据,就简单地使用预设数据返回。
事实上,三个月来,我们只是将wiki文本翻译成HTML。这不需要任何类型的数据存储,所以我们创建了一个名为MockWikiPage的类,它简单地保留了数据访问方法返回的预设数据。
最终,这些预设数据不足以用于我们想写的功能。我们需要真正的数据访问,而不是预设数据。所以我们创建了一个名为InMemoryPage的WikiPage的新派生物。这个派生实现了数据访问方法来管理维基页面的哈希表,我们保存在RAM中。
这使得我们在一整年里可以不断地编写功能。事实上,我们得到了FitNesse程序的第一个版本。我们可以创建页面,链接到其他页面,做所有奇特的wiki格式化,甚至用FIT运行测试。我们不能做的是保存我们的任何工作。
当要实现持久化的时候,我们再次考虑了MySQL,但是认为这在短期内不是必须的,因为将哈希表写入平面文件非常容易。所以我们实现了FileSystemWikiPage,它只是将功能移出到平面文件,然后我们继续开发更多的功能。
三个月后,我们得出了平面文件解决方案足够好的结论;我们决定放弃MySQL的想法。我们把这个决定推迟到没有回头的地步。
如果不是因为我们的客户决定要将wiki加入MySQL来达到他自己的目的,那这就是故事的结尾了。我们向他展示了让我们推迟这个决定的维基百科的架构。他一天后回来,整个系统在MySQL中工作。他只是写了一个MySqlWikiPage派生类,并实现它了。
我们曾经把这个选项和FitNesse捆绑在一起,但是没有人使用过它,所以最终我们放弃了它。即使写了派生类的客户也最终放弃了。
在FitNesse的开发早期,我们画出了业务规则和数据库之间的界线。除了简单的数据访问方法之外,该界限阻止了业务规则了解数据库的一切,而只是简单地数据访问接口。这个决定使我们推迟了一年以上数据库的选择和实现。它允许我们尝试文件系统选项,并且当我们看到更好的解决方案时,它允许我们改变方向。然而,当有人想要的时候,它并没有阻止,甚至阻碍了原来的方向(MySQL)。
事实上,我们没有运行18个月的数据库,这意味着在18个月内,我们没有模式问题,查询问题,数据库服务器问题,密码问题,连接时间问题以及所有其他讨厌的问题,这些当你启动一个数据库的时候遇到的他们的丑陋面目下的问题。这也意味着我们所有的测试都跑得很快,因为没有数据库减慢运行速度。
简而言之,划定界线有助于我们拖延和推迟决定,最终为我们节省了大量时间和精力。这就是一个好的架构师应该做的。
你画哪条线,什么时候画
你在重要的事物和不重要的事物之间画线。GUI对业务规则无关紧要,所以它们之间应该有一条线。数据库对于GUI来说并不重要,所以它们之间应该有一条线。数据库与业务规则无关,因此它们之间应该有一条线。
你们中的一些人可能已经拒绝了这些陈述中的一个或多个,特别是关于不关心数据库的业务规则的部分。我们中的许多人被教导认为数据库与业务规则有着千丝万缕的联系。我们有些人甚至确信数据库是业务规则的体现。
但是,正如我们将在另一章中看到的,这个想法是错误的。数据库是业务规则间接(indirectly)使用的工具。业务规则不需要了解模式,查询语言或任何有关数据库的其他细节。所有业务规则需要知道的是,有一组函数可以用来获取或保存数据。这允许我们把数据库放在一个接口后面。
你可以在图17.1中清楚地看到这一点。BusinessRules使用接口DatabaseInterface来加载和保存数据。DatabaseAccess实现该接口并执行实际数据库的操作。
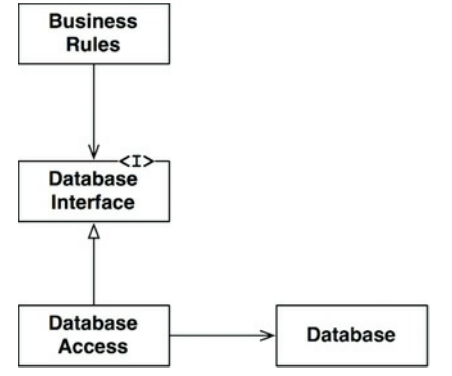
图17.1 数据库隐藏在接口后面
这个图中的类和接口是符号化的。在实际的应用程序中,将会有许多业务规则类,许多数据库接口类和许多数据库访问实现。但是,他们所有人都会遵循大致相同的模式。
边界线在哪里?边界线是通过继承关系绘制的,就在DatabaseInterface下面(图17.2)。
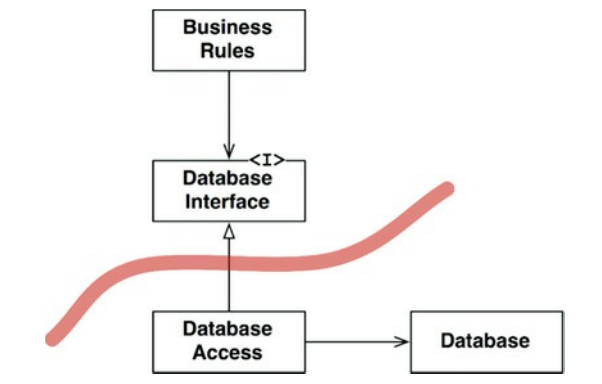
图17.2 边界线
注意从DatabaseAccess类出去的两个箭头。这两个箭头从DatabaseAccess类指出去。这意味着其他类都不知道DatabaseAccess类存在。
现在让我们拉回一点。我们将看看包含许多业务规则的组件,以及包含数据库及其所有访问类的组件(图17.3)。
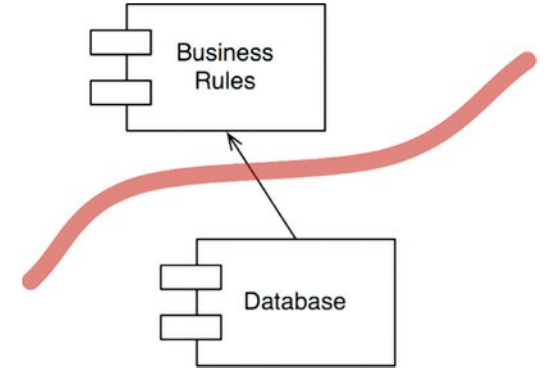
图17.3 业务规则组件和数据库组件
注意箭头的方向。数据库知道BusinessRules。BusinessRules不知道数据库。这意味着DatabaseInterface类位于BusinessRule组件中,而DatabaseAccess类位于Database组件中。
这条线的方向很重要。它显示数据库对BusinessRules无关紧要,但是没有BusinessRules,数据库就无法存在。
如果您觉得这很奇怪,只要记住这一点:数据库组件包含将BusinessRules调用转换为数据库查询语言的代码。要翻译的代码是知道BusinessRules的。
在绘制了这两个组件之间的边界线,并将箭头的方向设置为BusinessRules后,我们现在可以看到BusinessRules可以使用任何类型的数据库。数据库组件可以用许多不同的实现来替代——BusinessRules不关心。
数据库可以用Oracle或MySQL,Couch或Datomic甚至平面文件来实现。业务规则根本不在乎。这意味着数据库决策可以推迟,您可以专注于获得业务规则编写和测试,然后再决定数据库。
输入和输出是什么?
开发人员和客户经常对系统是什么感到困惑。他们看到GUI,并认为GUI是系统。他们根据GUI定义了一个系统,所以他们相信他们应该看到GUI可以立即开始工作。他们没有意识到一个非常重要的原则:IO是无关紧要的。4
起初可能很难把握。我们经常根据IO的行为来考虑系统的行为。例如,考虑一个视频游戏。你的体验是由界面(interface)主导:屏幕,鼠标,按钮和声音。你忘记了在这个界面背后有一个模型,即一组复杂的数据结构和功能驱动它。更重要的是,该模型不需要界面。它会高兴地执行它的职责,模拟游戏中的所有事件,而不会在屏幕上显示游戏。界面与模型(即业务规则)无关。
因此,我们再次看到GUI和BusinessRules组件由边界线分隔(图17.4)。我们再次看到,不太相关的组件取决于更相关的组件。箭头显示哪个组件知道另一个组件,因此哪个组件关心另一个组件,即GUI关心BusinessRules。
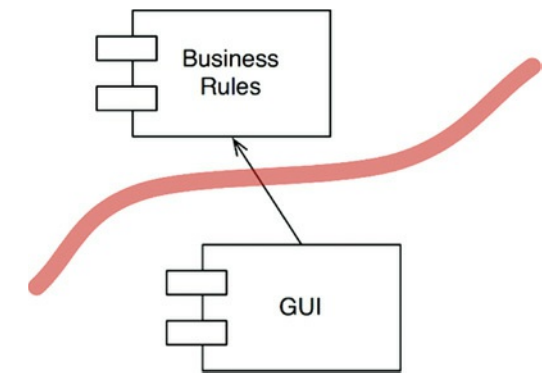
图17.4 GUI和BusinessRules组件之间的边界
在绘制了这个边界和这个箭头之后,我们现在可以看到GUI可以被任何其他类型的接口所取代,BusinessRules也不关心。
插件架构
总而言之,关于数据库和GUI的这两个决定创建了一种添加其他组件的模式。该模式与允许第三方插件的系统使用的模式相同。
事实上,软件开发技术的历史就是如何方便地创建插件来建立可扩展和可维护的系统架构的故事。核心业务规则与那些可选或者可以以多种不同形式实现的组件分开独立(图17.5)。
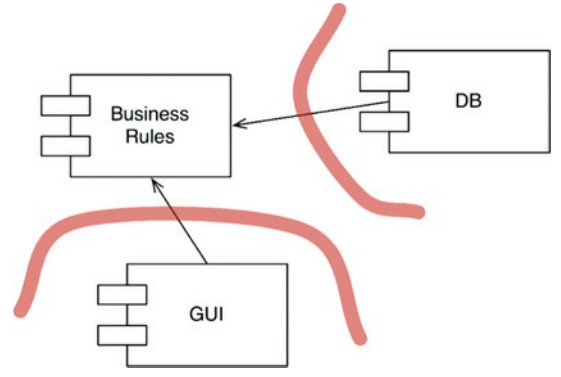
图17.5 插入进业务规则
由于本设计中的用户界面被认为是一个插件,因此我们可以插入许多不同类型的用户界面。它们可以是基于网络的,基于客户端/服务器的,基于SOA的,基于控制台的,或基于任何其他种类的用户界面技术。
数据库也是如此。由于我们选择将其作为一个插件来对待,所以我们可以用任何不同的SQL数据库,NOSQL数据库,基于文件系统的数据库,或者我们认为将来可能需要的任何其他类型的数据库技术。
这些替换可能不是微不足道的。如果我们的系统的初始部署是基于Web的,那么编写CS模式的UI的插件可能会很有挑战性。业务规则和新用户界面之间的某些通信很可能不得不重新进行。即便如此,从确定了插件结构的使用开始,我们至少已经做出了这样的改变。
插件小议
考虑ReSharper和Visual Studio之间的关系。这些组件由完全不同的公司完全不同的开发团队生产。事实上,ReSharper的制造商JetBrains居住在俄罗斯。微软当然居住在华盛顿州的雷德蒙德。很难想象两个开发团队如此独立的。
哪个团队可以危害对方?哪个队伍对另一个队伍是免疫的?从依赖结构看得出来(图17.6)。 ReSharper的源代码取决于Visual Studio的源代码。因此,ReSharper团队完全无法干扰Visual Studio团队。但是Visual Studio团队可以完全禁用ReSharper团队的东西,如果他们愿意的话。
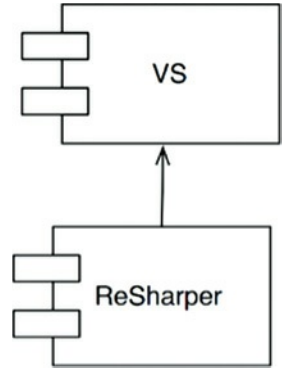
图17.6 ReSharper依赖于Visual Studio
这是一个非常不对称的关系,也是我们希望在我们自己的系统中拥有的关系。我们希望某些模块对其他模块免疫。例如,当有人更改网页格式或更改数据库模式时,我们不希望业务规则中断。我们不希望系统某个部分发生变化,导致系统的其他不相关部分中断。我们不希望我们的系统显示出这种脆弱性。
将我们的系统安排到插件体系结构中将创建防火墙,其间的更改无法传播。如果GUI插入业务规则,则GUI中的更改不会影响这些业务规则。
在有变化轴(axis of change)的地方绘制边界。边界一侧相比另一侧以不同的速率改变,并且由于不同的原因。
GUI相比业务规则在不同的时间以不同的速度改变,并且由于不同的原因,因此它们之间应该有一个边界。业务规则相比依赖注入框架在不同的时间以不同的速度改变,并且由于不同的原因,所以它们之间应该也有一个边界。
这只是单一责任原则(SRP)告诉我们在哪里绘制我们的界限。
小结
要在软件体系结构中绘制边界线,首先将系统划分为组件。其中一些组件是核心业务规则;另一些是包含与核心业务没有直接关系的必要功能的插件。然后你在这些组件中安排代码,使它们之间的箭头指向一个方向,即核心业务。
你应该认识到这是依赖倒置原则(DIP)和稳定抽象原则(SAP)的一个应用。依赖性箭头被安排从较低层的细节指向较高层的抽象。
1. The Java guys had dreams of server farms dancing in their heads. ↩
2. note:数据传输是双向的,如A和B通信,A发送给B,B接收后有返回回给A,这是一个过程,包含了四种消息协议。 ↩
3. data to which the programmer had no access, since all the programmer had was a name, address, and phone number. ↩
4. The IO is irrelevant. ↩