第十二章 组件
组件是部署的单元,组件是可被作为系统一部分部署的最小项。在Java中,组件指jar文件,在Ruby中,组件指gem文件,在.Net中,组件指DLL。在编译语言中,他们是二进制文件的集合。在解释语言中,他们是源文件的集合。所有语言中,他们是细粒度的部署品。
组件可以连接,成为单个可执行文件,或者他们聚合起来,成为单个压缩包,比如.war文件。或者他们可以独立的发布为分离的动态加载插件,比如.jar或.dll或.exe文件。不管最终组件怎样部署,良好设计的组件总可以被独立的部署,因此,可以独立开发。
组件简史
软件开发早年间,程序员得管理程序得内存位置和布局,程序里得代码第一行总是元语言,声明程序被加载得地址。
考虑以下简单得PDP-8程序,它是GETSTR得子例程,SETSTR的作用是把从键盘输入的字符串保存进系统缓存。以下例子对于练习GETSTR是一个小的单元测试程序。
*200
TLS
START, CLA
TAD BUFR
JMS GETSTR
CLA
TAD BUFR
JMS PUTSTR
JMP START
BUFR, 3000
GETSTR, 0
DCA PTR
NXTCH, KSF
JMP -1
KRB
DCA I PTR
TAD I PTR
AND K177
ISZ PTR
TAD MCR
SZA
JMP NXTCH
K177, 177
MCR, -15
*200是程序的起始命令,它告知编译器生成的代码运行是加载到地址200(8八进制)。
今天的大多数程序员对这类的程序很陌生,他们很少会去考虑程序被加载到计算机内存的哪里,但是早期这是程序员开始编程的第一件事。那时,程序是不可重定位的。
那早期应该怎样调用一个库函数?前面的代码说明了所使用的方法。程序员将库函数的源代码包含在它们的应用程序代码中,并将它们全部编译为单个程序。库程序保存在源代码中,而不是二进制文件中。
这种方法的问题是,在这个时代,设备很慢,内存很贵,因此很有限。编译器需要对源代码进行多次传输,但内存太有限,无法保存所有源代码。因此,编译器不得不通过慢设备,多次读取源代码。
这做法持续很长时间,程序库越大,编译越久。编译一个大型程序可用上数小时。
为了缩短编译时间,程序员从应用里,将函数代码库源码抽出,独立编译函数库,加载到一个已知的地址,如2000(8进制)。当运行程序时,先载入二进制函数库,再载入程序,内存分布如下图12.1
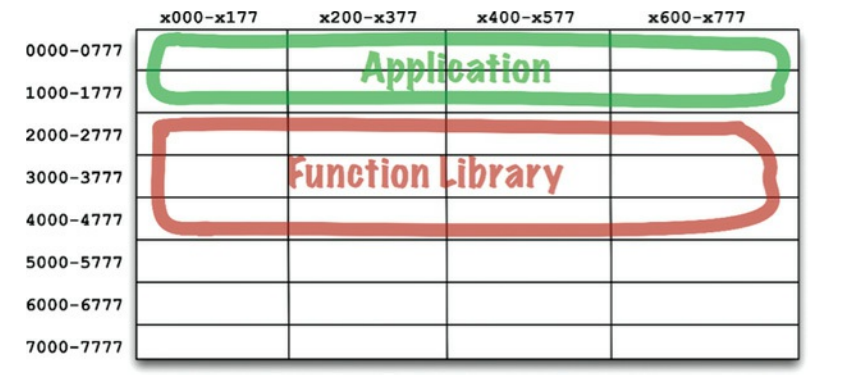 图12.1 早期内存分布
图12.1 早期内存分布
只要程序大小能装进0000(8进制)~1777(八进制)内,都能正常工作,但很快程序大小就超越了这个存储大小。一个办法,程序员将程序拆成两段,跳过中间的函数库的位置(图12.2)。
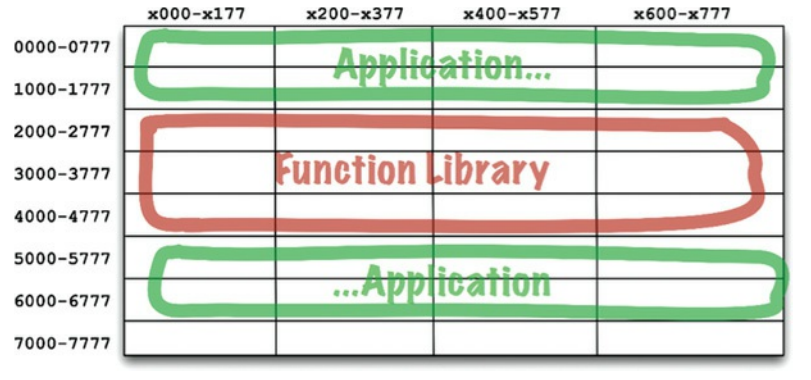 图12.2 程序拆成两段
图12.2 程序拆成两段
很明显,这并不是可持续的情况,程序员加入更多函数到函数库中,这也将超出函数库的容纳大小,需要再分配新的空间(对这个例子,从7000(8八进制)再存函数库多出的部分)。程序和库程序的分片将随着计算机内存越来越严重。
很明显,这得解决。
重定位
解决办法是重定位二进制内容。这想法很简单。编译器被改为输出的二进制代码可由一个智能的加载器重定位代码的内存位置。这个加载器被告知加载重定位代码的地址,重定位代码将由指令标志位告知加载器加载的哪些部分需要被修改并加载到为可选地址上。通常是在二进制中的任意内存引用地址加上起始地址。
现在程序员只要告知加载器库函数和应用的加载地址。事实上,加载器将接受这些二进制输入,只是简单的顺序摆放它们,当加载时再做重定位。这就允许程序员只加载使用到了的函数。
编译器也改变为把函数签名作为元数据放进重定位二进制里。如果程序调用库函数,编译器将把函数名解析为外部引用。如果程序定义了一个库函数,编译器将函数名作为外部定义。之后加载器一旦检测到已经加载的外部定义,将会连接上对应的外部引用。
这就是连接器的诞生。
连接器
连接加载器允许程序员把程序分成分离的可编译部分和可加载段部分。当关联的小的程序能被连接到对应的小的库,这很好。但20世纪60年代末70年代初。程序员更加积极,所写的程序规模更加的大了。
最后,连接加载器慢的难以忍受,函数库存储到慢设备,比如磁带中。但退一步来讲,即使是磁盘也很慢。用了这些慢设备,连接器解析二进制库得外部引用得读取几十次,也可能几百次。随着程序越来越大,库函数也越来越多,连接加载器甚至花费多于数小时来加载程序。
最后,加载和连接被分成两部分。程序员做慢的部分-连接的部分,把它放在独立的程序里,称作连接器,连接器的输出是已连接的重定位部分,可由重定位加载器可以迅速加载。这允许程序员用慢的连接器准备可执行文件,但最后,可以任意次的快速的加载。
这是20世纪80年代的发明。程序员用了C或其他高级语言,他们愈加积极,程序量也越大,成千上万的程序代码函数也司空见惯了。
源模块从.c文件编译成.o文件,由连接器执行后,输出可以可迅速加载的可执行文件。编译每个独立模块相对得快,但编译所有模块需要耗点时间。连接器将耗费很长的时间。
很多情况下,又要用掉一小时或更多时间了。
看起来程序员要无止境地减少这些编译时间了。贯穿20世纪60,70,80年代,所有加速工作流程地改变是因为程序员地积极,和他们所写地代码规模。他们似乎无法摆脱这长达一小时的周转时间。加载器已经飞快,编译连接耗时是瓶颈。
当然,我们正在经历墨菲定律的程序规模:
程序的增长将超出编译和连接花费的忍受时间。
但墨菲定律并不是唯一的想法。随着摩尔定律,在20世纪80年代末,这两个想法的现实碰撞了。摩尔赢得了。磁盘开始缩水,速度明显加快。电脑内存开始变得非常便宜,磁盘上的大部分数据都可以缓存在RAM中。计算机时钟速率从1 MHz增加到100 MHz。
到了20世纪90年代中期,连接耗费的时间的增速比程序员所写代码的增速的趋势降得厉害。大多情况下,连接的耗时减少到秒数量级了。对于一些小工作,使用连接加载器也很流畅了。
这是Active-X共享库的时代,也是.jar文件的开始时代。计算机和设备变得超乎想象的快,再一次,我们将连接操作放回了加载的时候做。我们可以在秒级时间连接数个.jar文件或者共享库文件,执行程序返回结果。所以组件插件架构诞生了。
今天我们在现存的应用上用上.jar文件,DLL或者共享库作为插件。如果你想对Minecraft做点修改,比如,你可以简单的将自己的.jar文件放到具体的目录上。如果你想在Visual Studio装Resharper插件,放入合适的DLL即可。
小结
这些在运行时可以插拔的动态二进制连接文件是我们架构的软件组件。过了50年,我们终于达到了组件插件架构,可以轻松了,而不用像曾经那样耗费巨大的努力。