第十三章 组件耦合

下面介绍的三个原则是要解决组件间的关系。这里我们又要考虑开发效率和逻辑设计的权衡。冲击构件结构的力量是技术性的,政策性的和不稳定性的。
无环依赖原则
组件依赖图遵守无环的设计
你是否有过工作了一整天,使得你写的东西跑起来了,然后回家,再第二天早上发现你写的东西不再能正常跑起来了?为什么?因为有些人比你工作的晚,改了你东西的依赖,我称作这种情况为“早晨综合征”。
“早晨综合征”发生在许多开发者可能修改了同样的源文件的开发模式。对于规模小,人数少的项目,这不是大问题。但项目数量一多,开发团队变多,“早晨综合征”真的就是噩梦了。几周都没有团队可能构建一个稳定的项目版本是非常罕见的。每个人都保有变更,并努力使得这些变更最终能和其他人的变更融合,能使系统跑起来。
过去这十年,有两个解决办法都是从通讯行业演变过来。第一个叫“每周构建”,第二个叫无环依赖原则(ADP)。
每周构建
每周构建常常用于中等规模的项目。所有的开发者在一周的前四天或略其他开发者的提交,所有开发者都在自己的代码副本里工作,不用考虑和其他人的工作集成。然后到了周五,把所有人的更变集成,再构建系统。
这方法很棒的是允许开发者在前四天独立地工作,缺点很明显,周五的集成非常的痛苦。
不幸的是,随着项目的增长,想要在周五完成项目的集成越来越不现实。集成的时间可能还要延伸到周六,有了周六这样的经历,足够让开发者觉得集成应该成周三就开始,这样开始集成的时间就慢慢移动到了一周的中间。
随着开发时间的占比对于集成时间逐渐下降,团队的开发效率也下降。最后的结果可想而知,开发者和项目管理者,可能宣布将集成时间改为两周一次,这足以能维持一段时间,但是集成时间随着项目规模也将增长。
最后,这种情况将导致灾难。为了维持效率,构建周期继续变长,但变长的构建周期将怎加项目的风险。集成和测试也将更难做,团队丢失了快速回馈的优势。
消除依赖循环
这个方法是分割开发环境为数个可发布组件。这些组件是数个工作单元,每个工作单元有单个开发者或单个团队负责。当开发者们将一个组件完成,他们可以发布这个组件供其他开发者使用。他们给这个发布组件一个发布号,把它放进某个目录下供娶她团队使用。这样这些开发者可以继续在自己的私有区域继续修改他们的组件。每个人只要用以发布的版本即可。
随着一个个新发布组件的可用,其他团队可以决定是否要马上切换到新的发布版本。如果决定不切换,继续用老版本即可。一旦他们时机成熟,那么就开始用新发布版本。
因此不会有团队受到于其他团队的影响,对一个组件的改变不必对其他团队有直接影响。每个团队能自行决定何时调整自己的组件兼容新版本。此外,集成只是小幅增加,所有开发者不必都聚在同一个时间点去集成他们所做的事情。
这是非常简单和理性的过程,也被广泛使用。为了使之更好运作,你必须管理组件依赖结构,不可以有循环依赖。如果在依赖结构中有循环依赖,那就不能避免“早晨综合症”。
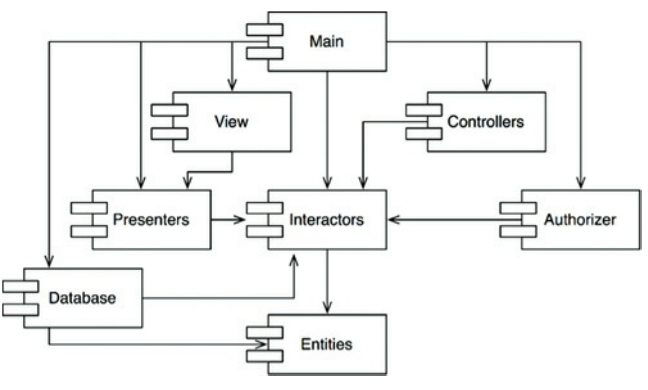
图14.1 典型的组件图
考虑图14.1的组件图。它展示了组合到应用里的相当典型的组件结构。对于这个样例,我们忽略掉应用的功能。重点来看组件的依赖结构。注意到这个结构是有向图。每个组件都是结点,依赖关系是有向线段。
注意一件事:不管从哪个组件开始,不可能沿着依赖关系由绕回起始地组件。这结构就是无环的。叫做有向无环图(DAG)。
现在考虑当Presenters组件的负责团队发布了新版本会发生什么?我们很容易找到受这个新版本影响的组件!你只要沿着依赖关系相反的指向。因此View和Main组件都收到影响。这两个组件的开发者们都将决定何时应该去集成新发布的Presenters。
再注意到Main新发布时,不会对系统的其他组件有影响。其他组件并不知道Main,也不关心Main的变化,非常的现象。这意味着Main的新发布影响相对小。当Presenters的开发者们想对此跑单元测试,他们只要构建他们开发的Presenters版本和当前使用的Interactors和Entities组件的版本。不需要其他模块的参与,非常好的现象。这意味着Presenters的开发者只需要相对较少的工作就能搭建测试,要变量考虑的变量相当少。
当发布整个系统时,这个过程是自底向上的,首先对Entities进行编译,测试,发布。再做Database和Interactors组件的,随后就是Presenters,View,Controllers,Authorizer,最后是Main组件。这个过程很清晰,容易处理。因为我们知道系统各个部分的依赖关系所以才知道了如何构建系统。
组件依赖图中有循环依赖的影响
假设有新的需求迫使我们在Entities组件中用了Authorizer组件的类,比如Entities组件中的User类用了Authorizer组件中的Permissions类,依赖图如14.2所示。
这个循环造成了很直接的问题。比如,Database组件的开发者要发布了,它得兼容Entities,由于有这个循环依赖,Database组件现在也得兼容Authorizer,但Authorizer依赖于Interactors。这使得Database难于发布了。Entities,Authorizer,Interactors实际上形成了一个大组件了,在这之上开发的人员都会经历“早晨综合症”。他们将互相钳制因为他们都用到了其他组件相同的版本。
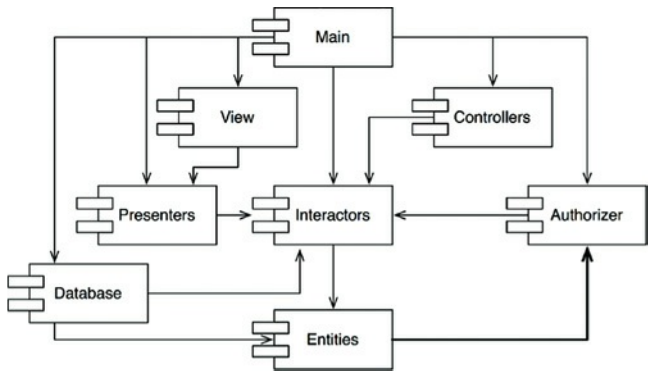
图14.2 一个循环依赖
但这只是麻烦的一部分。考虑当我们想测试Entities组件会发生什么?我们得构建Authorizer和Interactors组件,太烦了。如果真这样的话,这些组件间的耦合水平太糟了。
你可能在想,包含了这么多不同的库,这门多其他人的东西,就只为了跑自己类的单元测试?如果你细心一点,你会发现关系图里存在循环依赖,这会使组件很难独立。单元测试和发布都变得困难又容易出错。此外,构建问题随着模块的数量呈几何增长。还有,当依赖图里有循环依赖是,很难计算出构建系统的顺序,事实上,可能都没有正确的构建顺序。在一些语言中也将导致一些棘手的问题,比如Java,可能导致从编译后的二进制文件读取声明。
解除循环依赖
解除组件的循环依赖,使之复原呈DAG的依赖图是有可能的。有两种主要的机制:
- 应用依赖倒置原则(DIP),如图14.3中,我们创建了一个接口,接口中是User需要的方法。我们将接口放入Entities组件,接口的实现放入Authorizer组件,Entities和Authorizer的依赖就倒置了,进而解除了循环依赖。
- 创建一个新组件,Entities和Authorizer都依赖这个新组件。把问题的类都移到这个新组件。
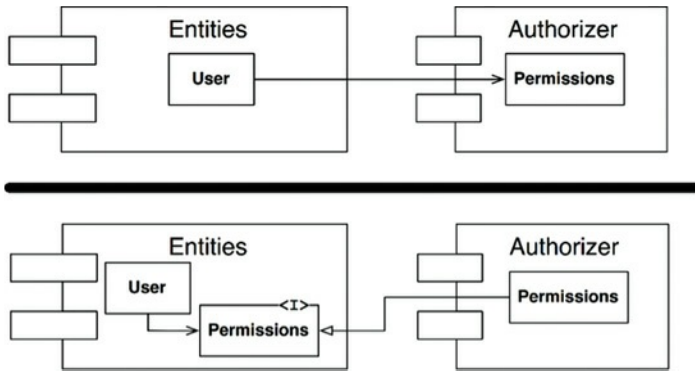
图14.3 Entities和Authorizer组件间的依赖转置
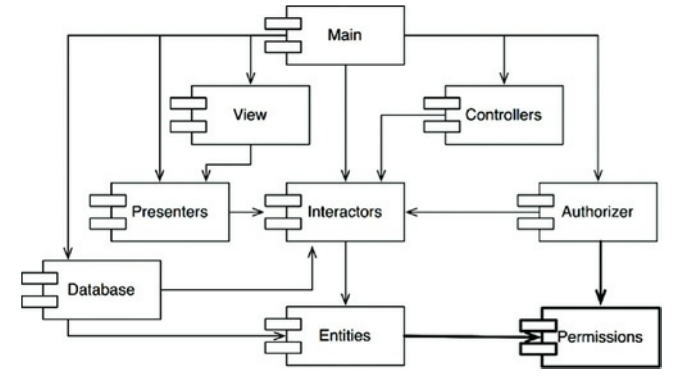
图14.4 Entities和Authorizer组件都依赖于新组件
抖动
第二个方法:组件结构在需求变化中是不稳定的。确实,随着应用程序的增长,组件依赖结构也增长,并且抖动,因此,我们得实时注意依赖结构中循环依赖的产生。但它产生时,要及时去解除,有时这意味着创建新组件,使得依赖结构增长,更容易出现循环依赖。
自上而下设计
这件事情我们讨论到现在,不可避免地推导出这样的结论:模块结构的设计不能自上而下。模块结构的设计不是设计系统的首要之一,而是随着系统的发展和变化逐渐演化。
一些读者可能会觉得这有违直觉,我们已经期望像组件一样的大粒度分解也将是高层次的功能分解。
当我们看见大粒度的组,比如组件依赖结构,我们相信这些组件某种程度上表示系统的功能,但这看起来并不是组件依赖图的属性。
事实上,组件依赖图对应用的功能描述得很少,相反,它们是应用程序的可构建性和可维护性的映射。这就是组件依赖图不能从项目初设计的原因。因为没有软件去构建和维护,也就不需要可构建性和可维护性的映射。但是随着越来越多模块在实现和设计的早期阶段迅速增长,在增长中需要管理依赖,所以项目的开发不会遇到“早晨综合症”。而且,我们想尽可能使改变局部化,所以我们关注SRP和CCP,把可能一起变化的类放到一起。
这种依赖性结构最重要的问题之一就是要隔离易变性。我们不希望频繁变化的组件以及反复无常的原因影响本来应该稳定的组件。 例如,我们不希望GUI的外观变化影响我们的业务规则。 我们不希望添加或修改报告影响我们的最高层政策。 因此,组件依赖关系图由架构师创建和塑造,以避免稳定的高价值组件受易变性组件的影响。
随着我们应用规模的增长,我们开始关注可重用原始的创建。这个点开始,CRP开始影响组件的组成,最后,如果有循环依赖出现,使用ADP消除依赖,组件依赖图抖动而增长。
如果我们一开始先于类的设计而去设计组件依赖,我们很可能会失败得很惨,我们并不知道公共的闭包,也不晓得任何一个可重用元素,我们几乎肯定会造出产生循环依赖的组件。因此组件依赖结构的增长和演变是随着系统逻辑设计而来的。
稳定依赖原则
依赖直接的稳定的东西
设计不可能完全是静态的,如果设计需要维护,保留些易变性是很必要的。满足共同封闭原则(CCP),我们创建了对特定类型变化敏感但对其他的变化免疫的组件。一些组件是被设计成易变的,因为我们期待它变化。
任何一个我们期待易变的组件都不能被很难变的组件依赖。否则,易变组件也很难改变了。
一个你设计成易变的模块,结果其他人简单依赖于这个组件,但导致了用的人很难改变,这是软件的反常情况。你的模块中的所有代码无需都变化,你的组件就能立刻更加适应变化。满足稳定依赖原则(SCP),我们保证你设计成的易于改变的模块不会被更难改变的模块依赖。
稳定性
稳定性是什么?像一枚立起的硬币,这个位置是稳定的吗?你可能会说“不是”。但是,除非有干扰,否则这枚硬币还是会长时间的保持这个立起状态。因此稳定性和改变的频率无直接关系。硬币并没变过,但很难想象它是稳定的。
韦伯词典描述稳定为“不易动”。稳定和工作需求的大小有关。一方面,硬币不稳定因为只要很少的工作就能把它放倒,另一方面,桌子是稳定的因为要用相当多的工作才能掀翻它。
和软件有什么关联。软件的组件难以改变的原因很多,比如大小,复杂性和清晰度等特征。我们将忽略这些因素,关注重要的。能确定一点,一个软件组件难以改变是因为很多其他的组件依赖于它。具有大量传入依赖关系的组件非常稳定,因为它需要大量工作来协调对所有依赖组件的任何更改。
如图14.5的稳定组件x。三个组件依赖于x,所以x有三个好理由不改变。我们说x对这三个组件负责,相反,x不依赖其他的组件,没有其他外来因素改变x,我们说他说独立的。
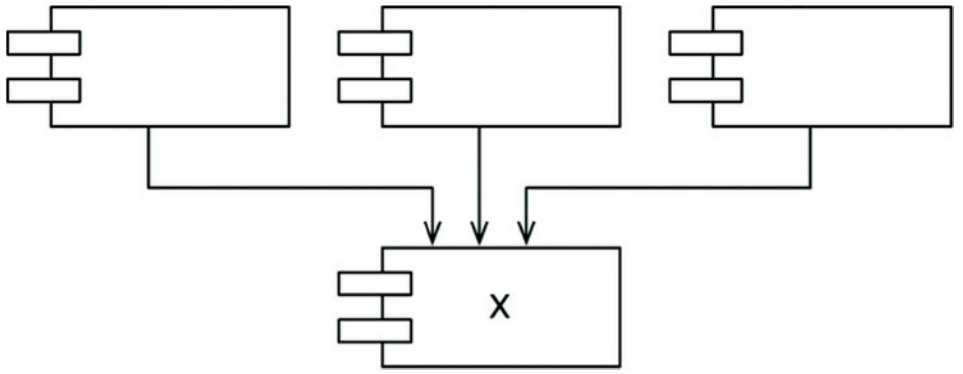 图14.5 组件x:一个稳定的组件
图14.5 组件x:一个稳定的组件
如图14.6的不稳定组件y,没有其他组件依赖y,我们称y是无责的,y依赖于其他三个组件,所以可能有来自三个外部的变化源,我们称y是依赖的。

图14.6 组件y:一个十分不稳定的组件
稳定指标
我们如何衡量一个组件的稳定程度?一个方法我们统计组件的依赖出度和入度,这些指标能帮助我们计算组件的位置稳定性。
- 扇入传入依赖。这个指标是外部组件的类依赖该组件类的数量。
- 扇出传出依赖,这个指标是该组件内部的类依赖外部组件的类的数量
- 不稳定度I I=扇出/(扇出+扇入),这个值的区间是[0,1],I=0表示组件最为稳定,I=1表示组件最不稳定。
扇入和扇出的指标通过计算问题外部组件的类数量和组件内的类的数量得到,如图14.7的例子。
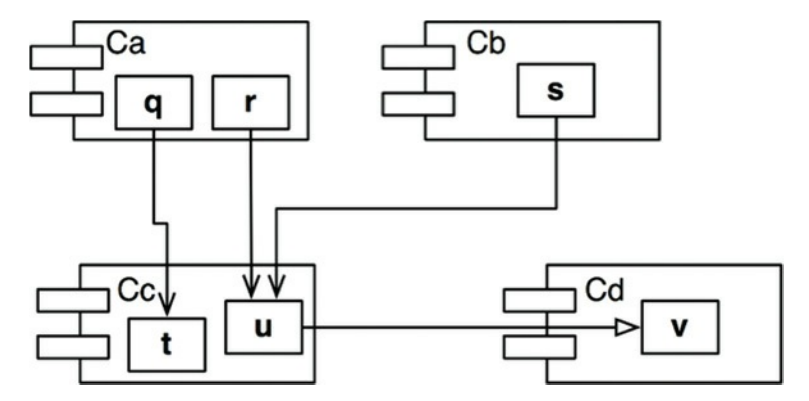
图14.7 例子
我们想计算组件Cc的稳定度,我们找到有三个外部的类依赖于Cc中的类,因此,扇出为3,Cc内的类有依赖一个外部的类,扇出为1,因此I=1/4。
在C++中,这些依赖一般可以通过#include语句表示,确实,当你组织源码使得每个文件都只有一个类的时候,I指标是最容易计算的。在Java中,我们可以通过数import语句和全限定名来计算I值。
当I值为1时,这意味着没有该组件(扇入为0)没有其他组件的依赖,该组件依赖的其他组件扇出大于0。这种情况是不稳定的,它是无责依赖的。没有依赖使得该组件没有理由不被改变,它依赖的组件可能给它充足的理由改变。
相反,当I值为0时,这意味着该组件依赖其他组件(扇入大于0),该组件(扇出为0)不被其他组件依赖。它是负责独立的。这种情况是非常稳定的,依赖它的组件的原因使得它很难改变,没有它依赖的组件迫使它改变。
这SDP表明一个组件的I值应该大于它依赖的组件的I值,也就是I值是随着依赖的方向递减的。
并非所有组件都应该是稳定的
如果一个系统中的所有组件都是最大稳定的,那这个系统将变得不可改变。这并不是理想的状态。我们设计的组件结构应该存在有稳定和不稳定的组件。如图14.8展示了一个三个组件的系统的配置。
顶部的两个可改变的组件依赖于底部的稳定组件。在图中把不稳定的组件放在顶部是很有用的,因为要是出现箭头向上的就能快速看出违反了SDP和ADP(之后介绍)。
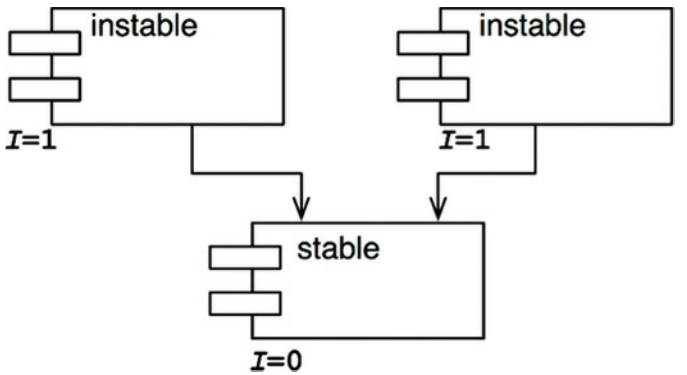
图14.8 一个由三个组件组成的系统的理想配置
如图14.9展示了违反了SDP的情况。
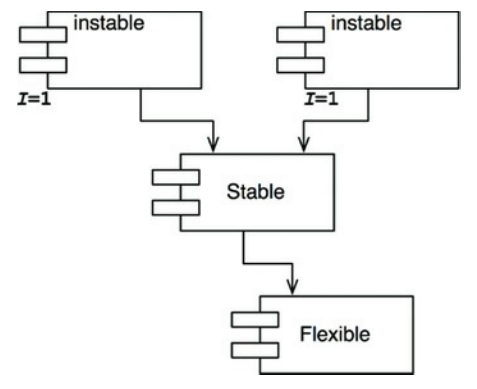
图14.9 违反SDP的情况
我们设计Flexible组件为可变的,我们得让Flexible具有不稳定性,但实现Stable组件的开发者缺依赖了Flexible组件,这违反了SDP,因为Stable组件的不稳定值I比Flexible组件的要小,这导致Flexible组件不再容易改变,对Flexible的改变将迫使我们处理依赖于它的包括Stable组件等等的组件。
如何解决这个问题呢?我们得想办法打破Stable和Flexible之间的依赖关系。那这个依赖是怎么来的呢?我们设想Flexible中的类C被Stable组件中的类U使用(如图14.10)。
我们可以见到的应用DIP,创建一个名为US的接口放到一个新组件UServer,确保类US中包含了类U要用的所有方法,之后我们让类C实现接口US(如图14.11)。这样我们打破了Stable和Flexible之间的依赖关系,迫使两个组件都依赖UServer,UServer是稳定的(I=0),Flexible保持了我们期望的不稳定性(I=1),所有的组件顺着箭头方向都是不稳定度I值递减的。
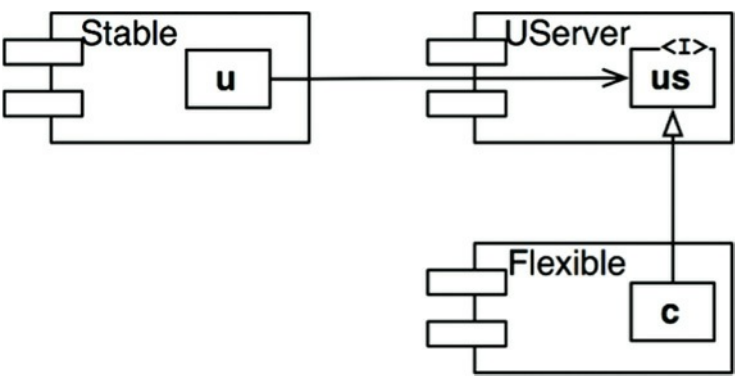
图14.11 类C实现了接口类US
抽象组件
你可能觉得我们在例子,又创建了一个组件,这很奇怪,尤其UServer中仅仅只有一个接口而已。这么个组件连可执行代码都没有!但是在诸如Java和C#等静态类型语言中,这是很普遍的,很必要的策略。这些抽象组件是十分稳定的,也是稳定度较低组件的理想依赖。
当我们用了诸如Ruby和Python等动态类型语言,就不需要这些抽象组件了和依赖了。在这类语言中,依赖结构更加简单,因为依赖转置无需接口,更不用实现接口。
稳定抽象原则
组件具备稳定性时,也应该具备抽象性。
我们该把高层策略放在哪?
一些系统中的软件并不会经常改变,这些软件体现了高层架构和策略决定。我们不想这些商业和架构的决定被违反,封装系统高层业务策略的软件应该放进稳定的组件(I=0),不稳定的组件只能包含我们想要快速容易改变的软件。
然而,如果高层策略放进稳定的组件,那蕴含这些策略的源代码将难以改变,这将使得整个架构不灵活。那我们该如何使得最大稳定的(I=0)也能足以应对改变呢?我们可以从开闭原则(OCP)中找到答案,这个原则告诉我们了这样一种可能而又理想的方案,创建的类灵活足以不修改而得以扩展。那种类满足这个原则的描述呢?答案是抽象类。
稳定抽象原则简介
稳定抽象原则将立起了稳定性和抽象性的联系,一方面,它描述了稳定组件应该具备抽象性,如他的稳定性那样而得以扩展。另一方面,它描述了不稳定的组件应该是具体实现的,因为不稳定允许具体实现的代码能容易变化。
因此,如果一个组件要稳定的话,它应该包含接口和抽象类使得它可以被扩展。稳定组件是可扩展的,灵活的,不会过度的限制架构。
SAP和SDP两者的结合多亏了DIP在组件中的应用。因为SDP描述依赖应该顺着稳定性的指向,SAP描述稳定性意味着要抽象,综合起来,依赖应该顺着要抽象的方向。
DIP这个原则不仅能安排类,也能安排没有灰色覆盖的类,不管这个类是不是抽象的。SDP和SAP的结合处理了组件,允许组件可以说部分抽象,部分稳定的。1
抽象度的衡量
我们定义用A值衡量一个组件的抽象度。这个值是是一个组件里接口和抽象类总数和这个组件的类总数的比值。
- Nc: 组件里的类的总数
- Na: 组件里的接口和抽象类的总数
- A: 抽象度A=Na/Nc
抽象度A值的区间为[0,1],A=0意味着组件里没有抽象性的类,A=1意味着组件仅仅只包含抽象性的类。
主次序线
让我们现在用某种方式定义不稳定度(I)和抽象度(A)的关系,我们建立一个A为纵坐标,I为横坐标的坐标系(如图14.12)。如果我们在图中画出两类“好理解”的点,我们发现在左上角(0,1)组件将达到最大稳定度和最大抽象度。在右下角(1,0)组件将达到最大不稳定度和最大具体性。
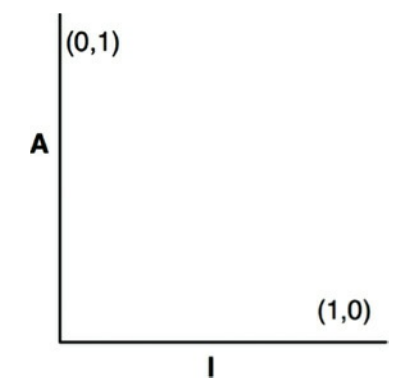
图14.12 I/A图
不是所有的组件只分为这两类,因为组件会经常有抽象度和稳定度的矛盾。比如一个常见的例子,从一个抽象类派生出另一个抽象类,这个派生类也就有了依赖,因此虽然是最大抽象的,但并非最大稳定的,这个依赖关系降低了它的稳定。
因为我们无法设计一个规则使得所有类在图上的点都只落在上述两个点。我们必须假设在A/I图上有一个点的轨迹定义了组件的合理位置。我们可以通过找出组件不应该在的区域来推断出该轨迹是什么,换句话说,通过检测排除的区域。
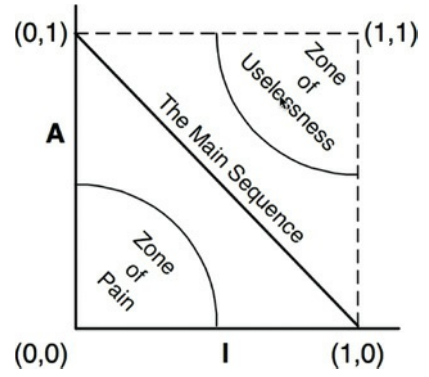
图14.13 排除的区域
痛苦区
考虑一个组件如果位于(0,0)的区域,即高稳定性而具体性,这么个组件并不理想,因为这是很死板僵硬的情况,它无法被扩展,因为它不是抽象的,由于高稳定性导致十分难以被修改。我们当然不希望良好设计的组件会靠近点(0,0),在(0,0)附近的外围区域我们称作痛苦区(Zone of Pain)。
一些软件事实上也在痛苦区内,比如数据库模式这个例子,数据库模式是十分不稳定,极度具体的且依赖度高的。这就是为什么面向对象应用和数据库间的接口是如此难以管理和为什么模式更新如此痛苦的原因。
另一个位于点(0,0)的例子是具体的工具类库,虽然这个库的不稳定度I值是1(译者注:感觉作者这里写错了,工具类库入度比重更大,I值应该是0),但它是非易失的。考虑String组件,尽管所有类中它都是具体的,但它很普遍的被这样用,并且改变它会造成混乱,因此String是非易失的。
非易失组件在(0,0)这个区域是无痛苦的,因为它们不太可能改变了。出于这个原因,在痛苦区的易失组件都是有问题的,在痛苦区的组件易失度越高,“痛苦”就越大。当然,我们可以把易失度当做图中坐标系的第三个维度,这么理解的话,图14.13中只显示了易失度为1的最痛苦的区域。
无用区
考虑在(1,1)附近区域的组件。这个位置也是非理想的,因为它有着最大抽象,且没有其他依赖它的组件。这么个组件是无用的,这个区域称为无用区。
在这个区域的软件实体是一种碎片,他们往往是剩下的抽象类,不存在实现他们的类。我们不时地在系统中发现它们,虽然在代码库中,但不被使用。
在无用区深处位置的组件肯定包含这样重要意义的实体碎片,很明显,这样的无用实体区域是不可取的。2
避免被排除的区域
看起来很明显,我们得易失组件应该尽可能远离上述的两个区域,
离这两个区域最大距离的点的轨迹是点(1,0)和点(0,1)的连线,我们称这条线为主次序(Main Sequence)。
位于主次序的组件对于稳定性不会“太抽象”,对于抽象性不会太“稳定”。既不会无用也不会特别痛苦。它取决于自身的抽象程度,取决于其他组件的具体程度。3
组件最理想的情况实在主次序线的两个顶点处。好的架构师将尽可能驱使他们的主要组件在这两个顶点。但是,在我的经验中,大系统中的一小部分组件既不完全抽象也不完全稳定。 如果这些部件处于或接近主次序线,则这些部件具有最佳特性。
距主次序线的距离
这是我们介绍的最后一个度量值,如果这个值描述了组件处于或接近主次序线,那么我们可以用一个值度量我们的组件离这个目标有多远。
- D: 距离,D=|A+I-1|,这个值的取值区间是[0,1],D值为0时表示这个组件表示的点就在主次序线上,D值为0时表示这个组件表示的点离主次序线最远。
有了这个度量值,一个设计可以被分析它满足主次序线的程度。每个组件的D值都可以计算得出来。任何D值不接近0的组件就可以被重新实验和重新组合。
设计的静态分析也变得有可能了。我们可以计算设计里的所有组件的D值得平均数和方差。我们是期待该设计满足,它的d值平均数和方差都接近于0得。方差值可以用于“控制限制”,识别出和其他组件相比“异常”的组件。
在图14.14的散点图中,我们看到大部分组件位于主次序线上,但其中一些点离平均值不止一个标准差(Z=1)。 这些异常的组件值得仔细研究。 由于某些原因,他们要么非常抽象,只有很少的其他组件依赖于它,要么非常具体,有许多组件依赖于它。
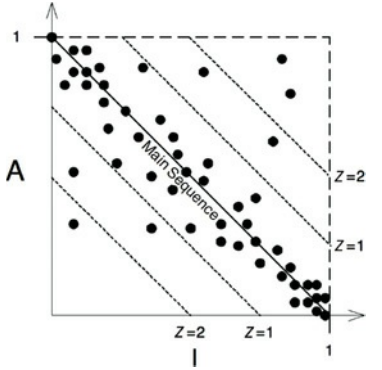
图14.14 组件的散点图
另一个用这个度量值的方法是随着时间绘制每个组件的D值。图14.15中的图形是这种图的模型。 你可以看到,在过去的几个版本中,一些奇怪的依赖关系已经蔓延到Payroll组件中。 该图显示了在D = 0.1时的控制阈值。 R2.1点已经超过了这个控制限制,所以我们有必要找出为什么这个组件远离了主次序线。
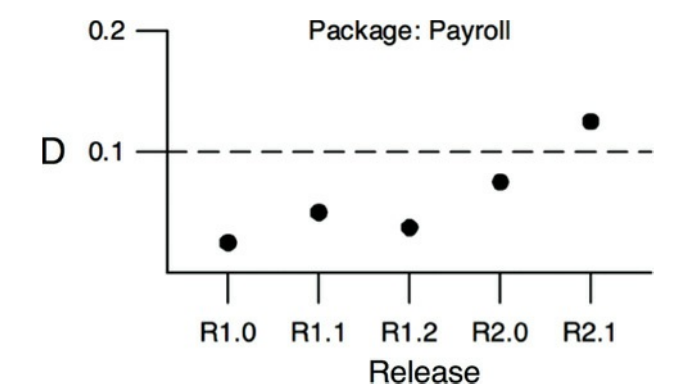
图14.15 随着时间绘制单个组件的D值图
小结
本章的依赖管理度量值描述一个设计满足于我认为的一个“好的”依赖和抽象的模式的度量。经验表明确定的依赖是好的,其他是不好的,这个模式影响了这个经验。但是,度量值并不是万能的,它只是在没有标准中的度量的标准,这些度量值并不完美,但我希望他们能帮得到你。
1. The DIP, however, is a principle that deals with classes—and with classes there are no shades of gray. Either a class is abstract or it is not. ↩
2. A component that has a position deep within the Zone of Uselessness must contain a significant fraction of such entities. ↩
3. It is depended on to the extent that it is abstract, and it depends on others to the extent that it is concrete. ↩