第三十四章 补充的章节

Simon Brown作
到目前为止,你所阅读的所有建议无疑将帮助您设计出更好的软件,这些软件由具有明确界限,明确职责和受控依存关系的类和组件组成。但事实证明,魔鬼在实施细节中,如果你不想这么做,最后一关也很容易。
让我们想象一下,我们正在建立一个网上书店,我们被要求执行的一个用例是客户能够查看他们的订单状态。尽管这是一个Java示例,但是这些原则同样适用于其他编程语言。让我们把清洁架构放在一边,看看设计和编码组织的一些方法。
层级划分包
第一种也许是最简单的设计方法是传统的横向分层体系结构,在这种体系结构中,我们将代码从技术角度分离。这通常被称为“层级划分包”。图34.1显示了这可能看起来像一个UML类图。
在这个典型的分层架构中,我们有一个Web代码层,一个层用于我们的“业务逻辑”,一个层用于持久化。换句话说,代码被水平分割成层,这些层被用来分类相似类型的东西。在“严格的分层架构”中,层应该仅依赖于下一个相邻的下层。在Java中,图层通常作为包来实现。如图34.1所示,层(包)之间的所有依赖关系都指向下方。在这个例子中,我们有以下的Java类型:
- OrdersController:一个Web控制器,就像一个Spring MVC控制器,处理来自Web的请求。
- OrdersService:定义与订单相关的“业务逻辑”的接口。
- OrdersServiceImpl:订单服务的执行。
- OrdersRepository:定义我们如何访问持久订单信息的接口。
- JdbcOrdersRepository:存储库接口的实现。
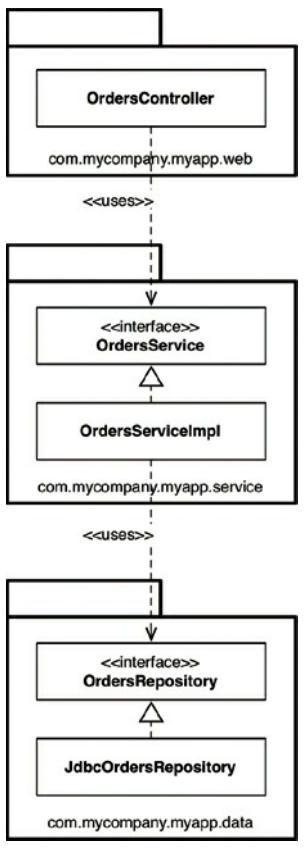
图34.1 层级划分包
在“展示域数据分层”中,Martin Fowler表示采用这种分层架构是开始的好方法。无独有偶,许多书籍,教程,培训课程和示例代码都可以帮助你找到创建分层架构的途径。这是一种非常快速的方式,可以在没有大量复杂情况下启动和运行。正如Martin所指出的那样,问题是一旦你的软件规模和复杂度增长,你会很快发现有三大代码是不够的,你需要进一步考虑模块化。
另一个问题是,正如Bob大叔已经说过的,分层架构不会呐喊任何关于业务领域的东西。将两个不同的业务领域并列的两层架构的代码放在一起,它们可能会看起来很相似:web,服务和存储。分层架构还存在另一个巨大的问题,但我们稍后会做到。
功能划分包
组织代码的另一个选择是采用“功能划分包”的风格。这是基于相关特性,领域概念或聚合根(aggregate roots,使用领域驱动的设计术语)的垂直切片。在我看到的典型实现中,所有类型都被放置在一个Java包中,以包的命名以反映分组的概念。
使用这种方法,如图34.2所示,我们拥有和以前一样的接口和类,但是它们都被放置在一个Java包中,而不是被分成三个包。这是一个从“层级划分包”风格的非常简单的重构,但代码的顶级组织现在呐喊一些关于业务领域的东西。现在我们可以看到,这个代码库与订单而不是Web,服务和存储有关。另一个好处是,在“查看订单”用例更改的情况下,查找所有需要修改的代码可能更容易。它们都坐在一个Java包中,而不是被分散开来。
我经常看到软件开发团队意识到他们在水平分层(“层级划分包”)和切换到垂直分层(“功能划分包”)方面存在问题。在我看来,这两者都不是最理想的。如果你已经阅读了这本书,你可能会认为我们可以做得更好,而且你是对的。
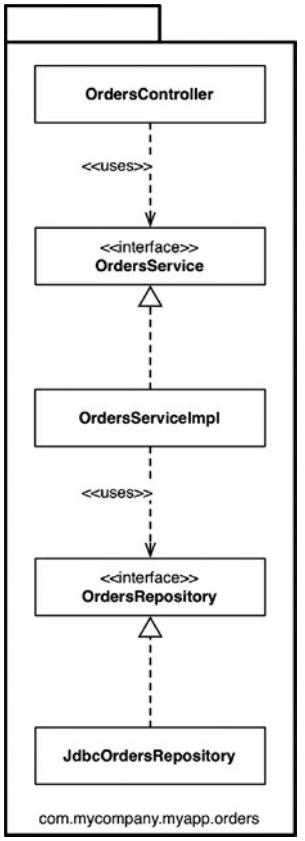
图34.2 功能划分包
端口和适配器
正如Bob大叔所说,“端口和适配器”,“六边形架构”,“边界,控制器,实体”等方法的目标是创建架构,其中以业务/领域为中心的代码是独立的并且与技术分离实现细节,如框架和数据库。总而言之,你经常会看到这样的代码库由“内部”(域)和“外部”(基础结构)组成,如图34.3所示。
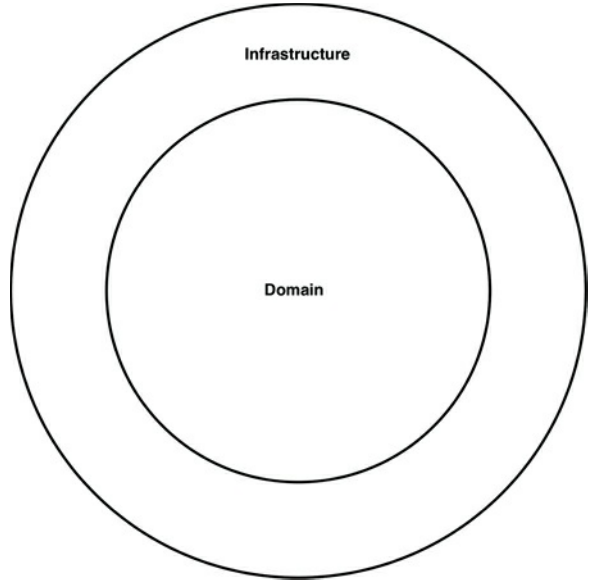
图34.3 具有内部和外部的代码库
“内部”区域包含所有领域概念,而“外部”区域包含与外部世界的交互(例如UI,数据库,第三方集成)。这里的主要规则是,任何时候,“外部”依赖于“内部”。图34.4显示了如何实现“查看订单”用例的一个版本。
这里的com.mycompany.myapp.domain包是“内部”,其他包是“外部”。注意依赖关系如何流向“内部”。敏锐的读者会注意到前面图中的OrdersRepository已经更名为简单的Orders。这来自领域驱动设计的世界,其中的建议是,“内部”的所有内容的命名应该用“无处不在的领域语言”来表述。换句话说,我们讨论“orders”当我们讨论域时,不是“orders repository”。
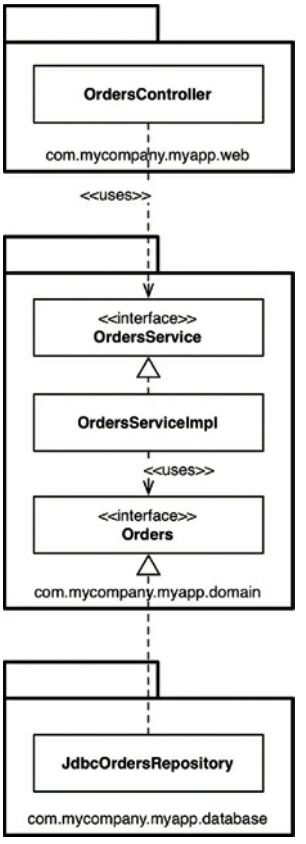
图34.4查看订单用例
另外值得指出的是,这是UML类图的简化版本,因为它缺少像交互器和对象这样的东西来跨越依赖边界封送数据。
组件划分包
尽管我完全同意关于SOLID,REP,CCP和CRP的讨论以及本书中的大部分建议,但是对于如何组织代码,我还是有一些不同的结论。所以我将在这里提出另一个选项,我称之为“组件划分包”。为了给你一些背景知识,我大部分职业生涯都花费在构建企业软件(主要是Java)上,跨越多个不同的业务领域。那些软件系统也有很大的不同。很多都是基于网络的,但其他的则是客户端-服务器,分布式,基于消息的或者其他的。虽然技术不同,但共同的主题是这些软件系统的架构基于传统的分层架构。
我已经提到了为什么分层架构应该被认为是不好的一些原因,但这不是全部。分层体系结构的目的是分离具有相同类型功能的代码。Web的东西从业务逻辑中分离,业务逻辑从数据访问中分离。正如我们从UML类图看到的,从实现的角度来看,一个层通常等同于一个Java包。从代码可访问性的角度来看,OrdersController能够依赖OrdersService接口,OrdersService接口需要被标记为public,因为它们在不同的包中。同样,OrdersRepository接口需要被标记为public,这样才能通过OrdersServiceImpl类在repository包之外看到它。
在一个严格的分层架构中,依赖箭头总是指向下方,层次只取决于下一个相邻的下层。这最后创建一个漂亮的,干净的,无环的依赖关系图,这是通过引入一些关于代码库中的元素如何相互依赖的规则来实现的。这里最大的问题是我们可以通过引入一些不良的依赖来作弊,但是仍然会创建一个很好的非循环依赖关系图。
假设你雇佣了一个新人加入你的团队,并且给了新人另一个orders相关的用例来实现。由于这个人是新人,他想要给他留下一个很大的印象,并尽快实施这个用例。坐了几杯咖啡几分钟后,新来者发现一个现有的OrdersController类,所以他决定这是新的orders相关网页的代码应该写入的地方。但是它需要一些来自数据库的命令数据。新来者有一个顿悟:“哦,也有一个OrdersRepository接口已经建成。我可以简单地依赖注入实现到我的控制器。完美!“经过几分钟的实现,网页正在运行。但是最终的UML图如图34.5所示。
依赖性箭头仍然指向下方,但OrdersController现在另外绕过OrdersService,而OrdersService表达了用例。这个组织通常被称为一个松散的分层结构,因为层允许跳过他们相邻的邻居。在某些情况下,这是预期的结果——例如,如果你尝试遵循CQRS模式。在许多其他情况下,绕过业务逻辑层是不受欢迎的,特别是如果业务逻辑负责确保授权访问单个记录。
虽然新的用例起作用,但它可能没有按照我们预期的方式实现。当我作为一名顾问访问团队时,我发现很多这种情况,当团队开始通常第一次看到他们的代码真实的样子时,通常会发现这种情况。
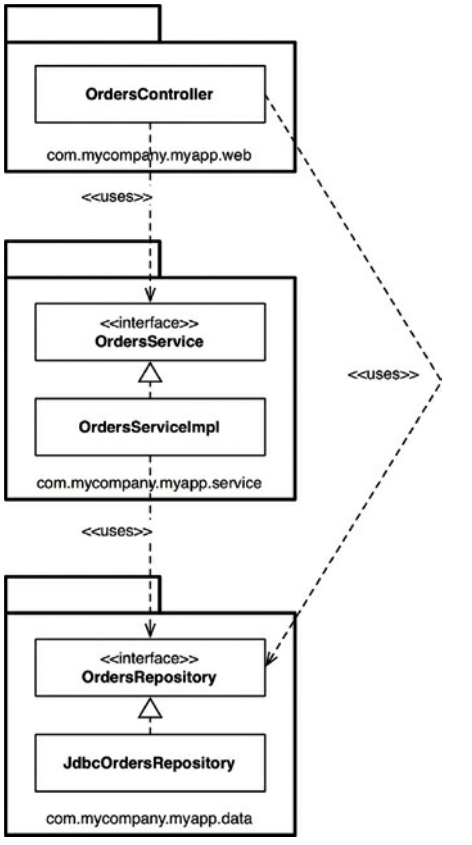
图34.5 松散的分层架构
我们在这里需要指导原则——架构原则——就是说“Web控制器不应该直接访问存储”。这个问题当然是强制的。我遇到的很多团队只是简单地说:“我们通过严格的纪律和代码审查来执行这个原则,因为我们相信我们的开发人员。”这种信心非常令人振奋,但是我们都知道在预算和期限越来越近的时候会发生什么。
少得多的团队告诉我,他们使用静态分析工具(例如,NDepend,Structure101,Checkstyle)在构建时检查并自动执行架构违规。你可能自己看到过这样的规则,它们通常表现为正则表达式或通配符字符串,它们声明“在/web包中的类型不应该访问/data包中的类型”,并在编译之后执行检查。
这种方法有点粗糙,但它可以做到这一点,报告违反了定义为团队的体系结构原则,并且(你希望)构建失败。这两种方法的问题是它们都是错误的,反馈回路比它应该更长。如果放任不管,这种做法可以将代码库变成一个“大泥潭”。如果可能的话,我个人喜欢用编译器来强制我的架构。
这将我们带到“组件划分包”选项。对于我们迄今为止所看到的所有内容来说,这是一种混合方法,其目标是将与单个粗粒度组件相关的所有责任捆绑到一个Java包中。这是关于以服务为中心的软件系统的观点,这也是我们所看到的微服务体系结构。与端口和适配器将Web视为另一种传送机制的方式相同,“组件划分包”将用户界面与这些粗粒度组件分开。图34.6显示了“查看订单”用例的样子。
实质上,这种方法将“业务逻辑”和持久化的代码捆绑成一个单一的东西,我称之为“组件”。Bob大叔在本书前面提出了他对“组件”的定义:
组件是部署单元,它们是可以作为系统的一部分部署的最小的实体。在Java中,它们是jar文件。
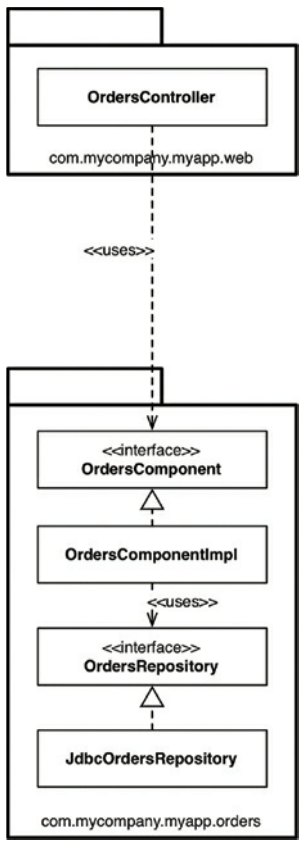
图34.6 查看订单用例
我对组件的定义略有不同:“一个漂亮的整洁的接口背后的一组相关的功能,它驻留在一个像应用程序一样的执行环境中。”这个定义来自我的“C4软件体系结构模型”,它是一个简单的层次结构以容器,组件和类(或代码)的方式考虑软件系统的静态结构。它说,一个软件系统由一个或多个容器(例如,Web应用程序,移动应用程序,独立应用程序,数据库,文件系统)组成,每个容器包含一个或多个组件,而这些组件又由一个或更多类(或代码)。是否每个组件都驻留在一个单独的jar文件中是一个正交的问题。
“组件划分包”方法的一个关键好处是,如果你正在编写需要对订单进行处理的代码,那么只需要一个地方——OrdersComponent。在组件内部,问题的分离仍然保留,所以业务逻辑与数据持久性是分开的,但这是消费者不需要知道的组件实现细节。这类似于如果采用微服务或面向服务的体系结构(可能包含与处理订单有关的所有内容)的单独的OrdersService。关键的区别是解耦模式。你可以将单一应用程序中定义明确的组件视为微服务体系结构的基础。
恶魔在执行细节中
从表面上看,这四种方法看起来都是不同的组织代码的方式,因此可以被认为是不同的架构风格。不过,如果你的实现细节错误的话,这种看法很快就会解开。
我经常看到的东西是过度自由地使用Java等语言中的public访问修饰符。就好像我们作为开发者本能地使用public关键字一样,无需思考。这是在我们的肌肉记忆。如果你不相信我,请参阅GitHub上的书籍,教程和开源框架代码示例。无论代码库采用何种架构风格——水平层,垂直层,端口和适配器,还是其他方式,这种趋势都是显而易见的。将所有类型标记为public意味着没有充分利用编程语言在封装方面提供的功能。在某些情况下,没有任何东西可以阻止某人编写代码来直接实例化具体的实现类,从而违反了预期的架构风格。
组织和封装
另一种方式来看待这个问题,如果将Java应用程序中的所有类型都声明为public,那么这些包就是一个组织机制(一个分组,就像文件夹一样),而不是用于封装。由于public类型可以从代码库中的任何地方使用,因此可以有效地忽略这些包,因为它们提供的实际价值很小。最终的结果是,如果你忽略了这些包(因为它们没有提供任何封装和隐藏手段),那么你有意创建哪种架构风格并不重要。如果我们回头看一下示例的UML图,那么如果所有类型都被标记为public,那么Java包就变成不相关的细节。实质上,当我们过度使用这个关键字时,本章前面提到的所有四种架构方法都是一样的(图34.7)。
仔细看看图34.7中的每个类型之间的箭头:无论尝试采用哪种架构方法,它们都是完全相同的。从概念上讲,这些方法是非常不同的,但在语法上它们是相同的。此外,你可以争辩说,当你把所有的类型都公开时,你真正拥有的只有四种方法来描述传统的水平分层结构。这是一个巧妙的技巧,当然没人会声明所有Java类型为public。除了我见过的一些人确实这么做了。
Java中的访问修饰符并不完美,但忽略它们只是自找麻烦。将Java类型放入包中的方式实际上可以对适当地应用Java访问修饰符时这些类型的可访问性(或不可访问性)产生巨大影响。如果回头看这些软件,并且(通过图形淡化)标记访问修饰符可以变得更加严格的类型,那么这张图片看起来就变得非常有趣了(图34.8)。
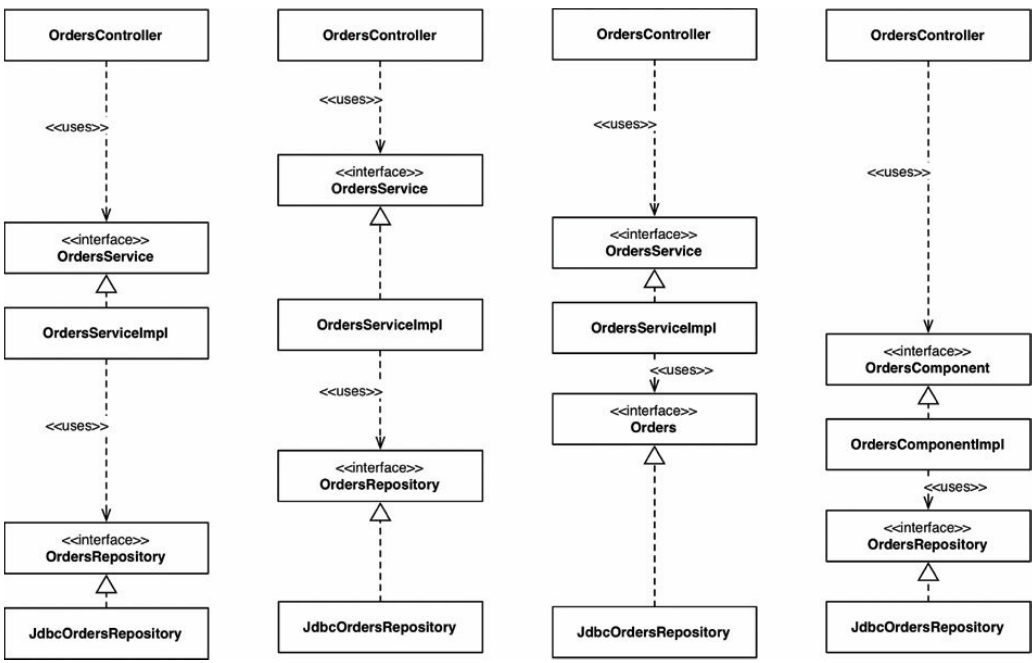
图34.7 所有四种架构方法都是一样的
从左到右,在“层级划分包”方法中,OrdersService和OrdersRepository接口需要需要声明为public,因为它们具有来自定义包之外的类的入站依赖性(inbound dependencies)。相比之下,实现类(OrdersServiceImpl和JdbcOrdersRepository)可以做得更严格(包protected)。没有人需要了解他们;他们是一个实现细节。
在“功能划分包”的方法中,OrdersController提供了进入包装的唯一入口点,所以其他一切都可以设包为protected。这里要注意的一点是,在这个包之外的代码库中没有其他任何东西可以访问与订单相关的信息,除非它们通过控制器。这可能是也可能不是可取的。
在端口和适配器方法中,OrdersService和Orders接口具有来自其他包的入站依赖关系,因此需要声明为public。同样,实现类可以在运行时进行包protected和依赖注入。
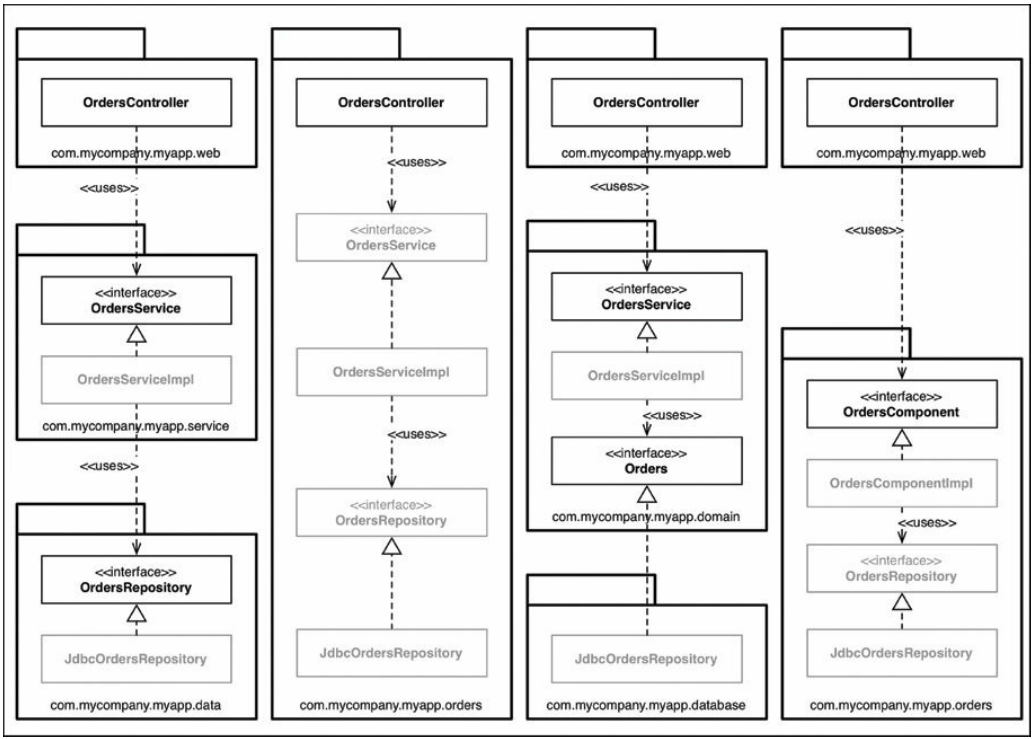
图34.8 灰色类型是可以使访问修饰符更具限制性的地方
最后,在“组件划分包”方法中,OrdersComponent接口具有来自控制器的入站依赖性,但其他所有内容都可以被封装保护。你拥有的public类型越少,潜在的依赖关系就越少。现在没有办法可以在这个包之外的代码直接使用OrdersRepository接口或实现,所以我们可以依靠编译器来执行这个架构原则。尽管你需要为每个组件创建一个单独的程序集,但是可以使用internal关键字在.NET中执行相同的操作。
为了清楚起见,我在这里描述的是一个单一的应用程序,其中所有的代码都驻留在一个源代码树中。如果你正在构建这样一个应用程序(和许多人),我肯定会鼓励你依靠编译器来执行你的架构原则,而不是依靠自律和后编译工具。
其他解耦模式
除了使用的编程语言之外,通常还有其他方法可以将源代码依赖关系解耦。使用Java,你可以使用OSGi和新的Java9模块系统等模块框架。使用模块系统时,如果使用得当,可以区分public的类型和发布的类型。例如,你可以创建一个订单模块,其中所有类型都标记为public,但只发布这些类型的一小部分用于外部使用。这得等很长一段时间了,但我对Java9模块系统将会给我们提供另一种工具来构建更好的软件,并再次激发人们对设计思想的兴趣,我感到非常高兴。
另一个选择是通过在不同的源代码树中分割代码,在源代码级别解耦你的依赖关系。如果我们以端口和适配器为例,我们可以有三个源代码树:
- 业务和域的源代码(即独立于技术和框架选择的所有东西):OrdersService,OrdersServiceImpl和Orders
- Web的源代码:OrdersController
- 数据持久化的源代码:JdbcOrdersRepository
后两个源代码树对业务和域代码具有编译时间依赖性,而业务和域代码本身并不知道有关Web或数据持久性代码的任何信息。从实现的角度来看,你可以通过在构建工具中配置单独的模块或项目(例如,Maven,Gradle,MSBuild)来实现这一点。理想情况下,你可以重复使用此模式,为应用程序中的每个组件提供单独的源代码树。然而,这是一个非常理想的解决方案,因为存在与以这种方式分解源代码相关的真实世界的性能,复杂性和维护问题。1
一些人为了端口和适配器代码而采取的简单方法是只有两个源代码树:
- 域代码(“内部”)
- 基础结构代码(“外部”)
这很好地映射到了图中(图34.9),很多人用来总结端口和适配器体系结构,并且从基础结构到域有编译时间依赖性。

图34.9 域和基础结构代码
这种组织源代码的方法也可以工作,但要注意潜在的权衡。这就是我称之为“端口和适配器的派里弗里克反模式”(Périphérique anti-pattern of ports and adapters)。法国巴黎市有一条叫做“派里弗里克大道”(Boulevard Périphérique)的环形公路,它可以让你环游巴黎,而不必进入城市的复杂环境。将所有基础结构代码都放在一个源代码树中意味着你的应用程序的某个区域(如Web控制器)中的基础结构代码可能有可能直接调用应用程序的其他区域(例如数据库存储库)中的代码,而不通过域导航。如果忘记将适当的访问修饰符应用于该代码,则尤其如此。
小结:补充建议
本章的重点在于强调如果不考虑执行策略的复杂性,那么你的最佳设计意图可能会很难施展。考虑如何将所需的设计映射到代码结构,如何组织代码以及在运行时和编译期间应用哪些解耦模式。在适用的情况下保留选项,但切合实际,并考虑到你的团队规模,技能水平以及解决方案的复杂性,并结合你的项目时间和预算限制。还要考虑使用编译器来帮助你执行你选择的架构风格,并且注意其他领域(如数据模型)中的耦合。魔鬼在实现细节中。
1. This is very much an idealistic solution, though, because there are real-world performance, complexity, and maintenance issues associated with breaking up your source code in this way. ↩